

The Volume Illusion: Why Your Content Factory Scales to Zero in the Era of SGE
The hidden flaw killing your search traffic. Discover the breakthrough framework Next Big App uses to automate schema and dominate AI-driven search.

For nearly two decades in growth and SaaS, I’ve watched marketing teams fall into the same predictable trap: they treat growth as a volume game.
If ten articles net you 10,000 visitors, then a hundred articles must net you 100,000.
That linear assumption is dead.
In 2026, scaling content velocity doesn’t build authority; it just burns cash.
Google has fundamentally shifted from a search engine that refers traffic to an Answer Engine driven by AI Overviews (SGE).
When zero-click searches are the default baseline, running a traditional, high-volume content factory breaks completely.
The algorithm no longer rewards the sheer mass of words you publish. It rewards Information Gain and Machine-Readable Structure.
If your growth playbook is still built on mass-producing synthesized articles that repackage existing web insights, your organic distribution is about to scale to zero.
Here is the reality of how Google’s modern backend operates—and how we build LLM-ready architecture at Next Big App to survive it.
The RAG Filter: Why “More” is No Longer “Better”
When Google’s SGE generates an overview on the SERP, it relies on a RAG (Retrieval-Augmented Generation) framework.
It doesn’t just guess the next word; it pulls data from trusted index sources, extracts specific text chunks, and synthesizes them into a direct answer.
During this retrieval phase, Google applies a strict algorithmic filter: Information Gain.
If your article merely summarizes the same concepts already sitting in the top 10 search results, your Information Gain score is flat zero.
The RAG mechanism doesn’t need an eleventh version of the same opinion. It discards your page before it ever reaches the AI overview window.
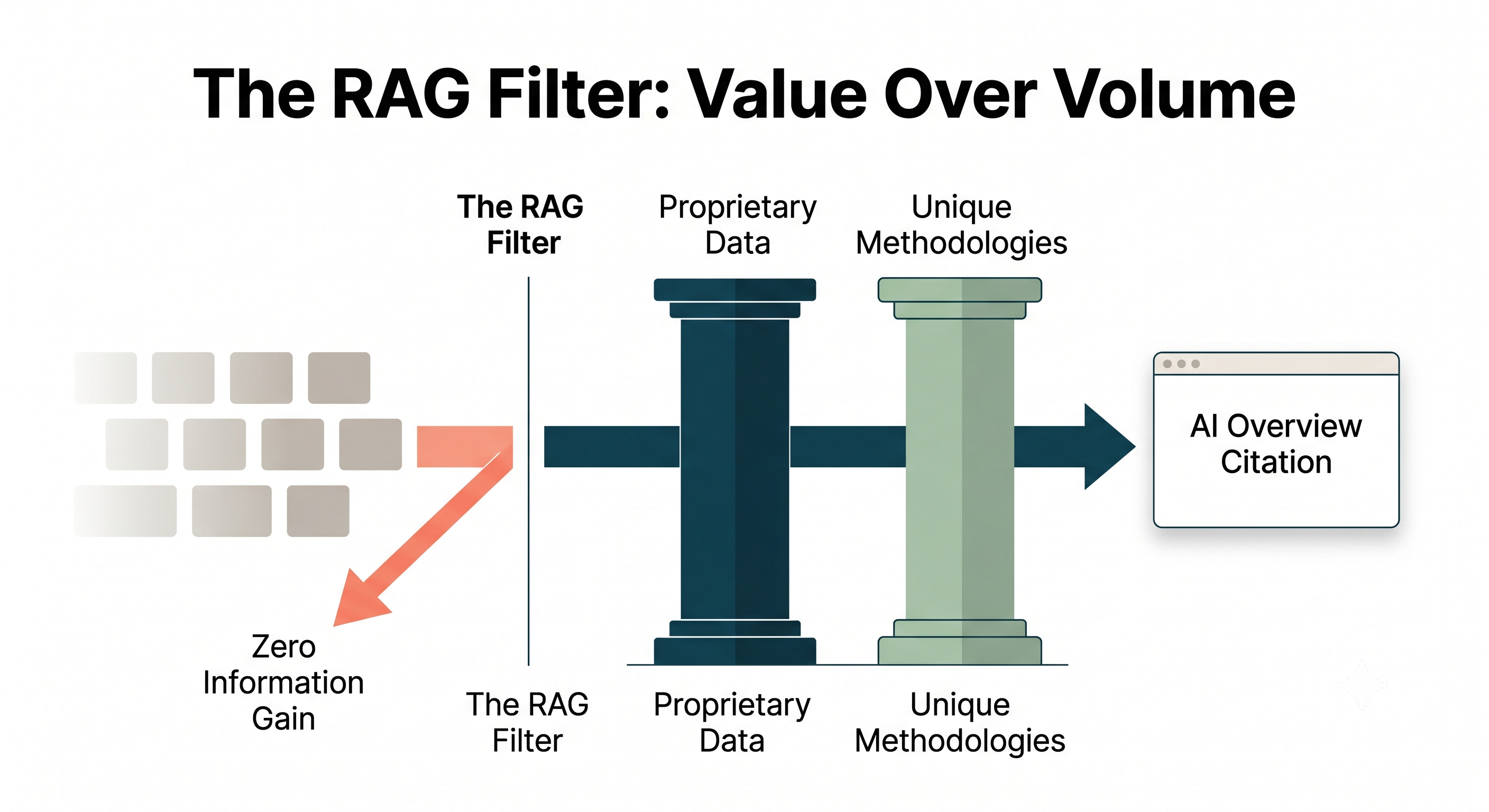
To win a citation in an AI-driven search world, your content strategy must shift away from volume and lean heavily into two non-negotiable pillars:
Proprietary Data: First-party surveys, internal platform metrics, and original case studies that cannot be scraped or simulated elsewhere.
Unique Methodologies: Proprietary frameworks and named intellectual property unique to your leadership team, explicitly fed to the crawler via
Quotationschema.
From Keywords to Entities: The Semantic Blueprint
Outsiders think SEO is a copywriting problem. Operators know it’s a database architecture problem.
Traditional content factories focus on keyword density. SGE, powered by Gemini and advanced LLM variants, completely ignores keyword stuffing.
First, we need to understand one thing very clearly: search engines now crawl the internet for a single reason, to answer one question:
“Does this site contain information I can classify and connect in meaningful new ways to other facts, events, brands, people, or entities?”
It reads text to identify entities, unique, identifiable concepts (companies, products, specific methodologies) and maps how they relate to one another in its global Knowledge Graph.
If your brand and the specific solutions you offer are not explicitly modeled as interconnected “Nodes”, the AI cannot map your authority.
At Next Big App, we map our content silos using a graph database framework like Neo4j or ArcadeDB before we ever publish a word. This allows us to pre-simulate exactly how an AI engine will interpret our brand ecosystem.
A strong content strategy should not start with isolated keywords. It should start with a clear knowledge structure that helps search engines and AI systems understand your brand’s role in the market.
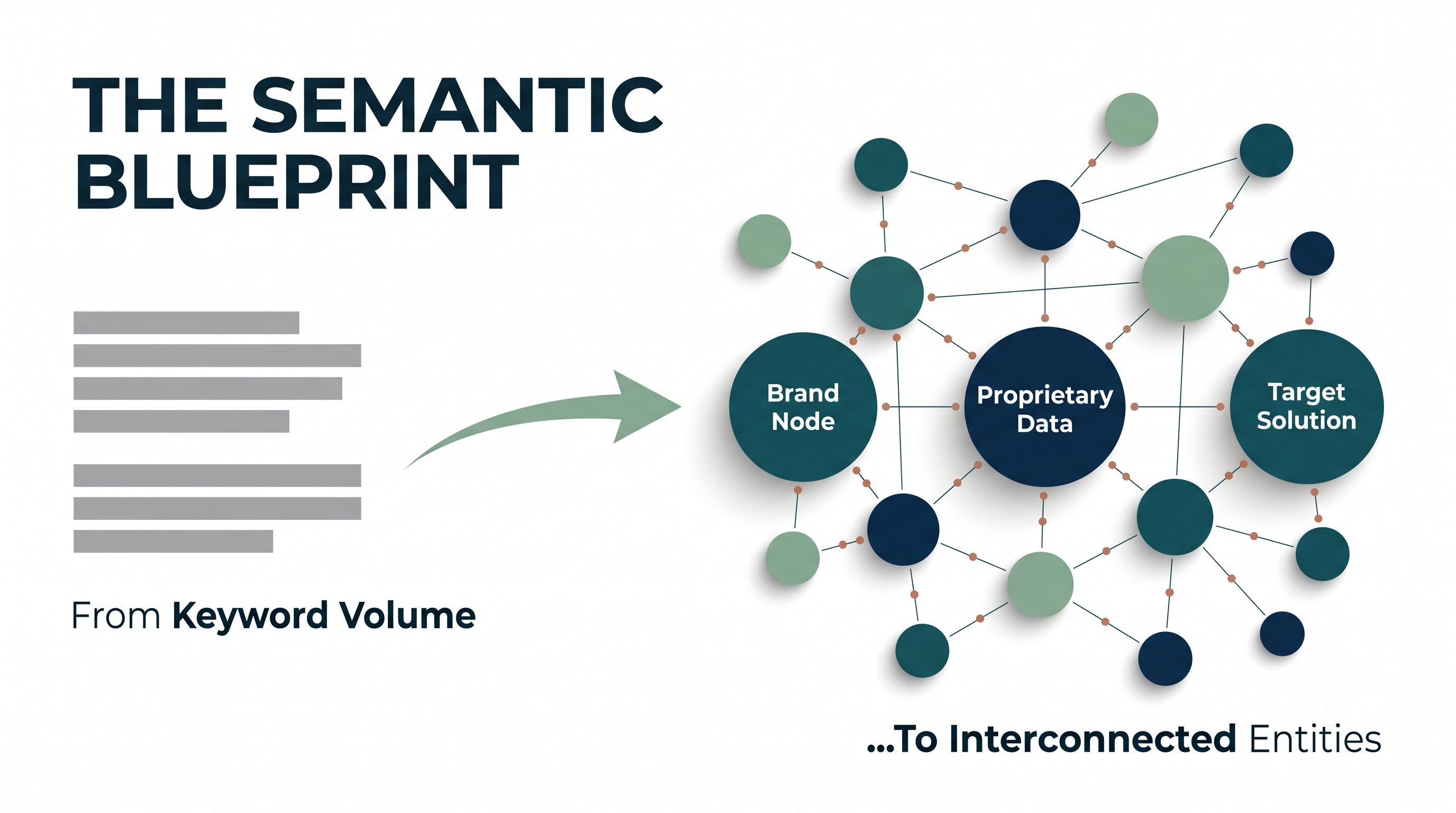
The core flow looks like this:
Your company develops a proprietary framework: This gives your brand a unique point of view instead of making it sound like every other company in the category.
The framework addresses a specific customer pain point: The content should clearly explain the problem your audience is struggling with, why it matters, and why existing approaches are not enough.
The customer pain point connects naturally to a target solution: Your product or service should appear as the logical resolution to the problem, not as a forced sales pitch.
This creates a semantic chain: Company → Framework → Pain Point → Solution
This matters because AI search systems do not only look for keyword matches. They look for clear relationships between entities, concepts, problems, and answers. When your content repeatedly explains your framework, applies it to real customer problems, and connects it to a concrete solution, your brand becomes easier to understand, cite, and recommend.
In practice, this means you are not just publishing articles for traffic. You are building a recognizable authority map around your company. Over time, your brand becomes associated with a specific way of solving a specific problem.
When your site architecture mirrors this clean, conflict-free semantic web, Google’s crawlers can instantly parse your contextual relevance.
Automating the Structural Pipeline
Mapping your internal data structure is useless if the search engine can’t ingest it instantly.
You need to translate your content universe into the native language of AI crawlers: JSON-LD (Schema Markup).
Writing this code manually is an operational bottleneck. Instead, we use LLM-powered automation pipelines via API integrations to handle it dynamically at scale.
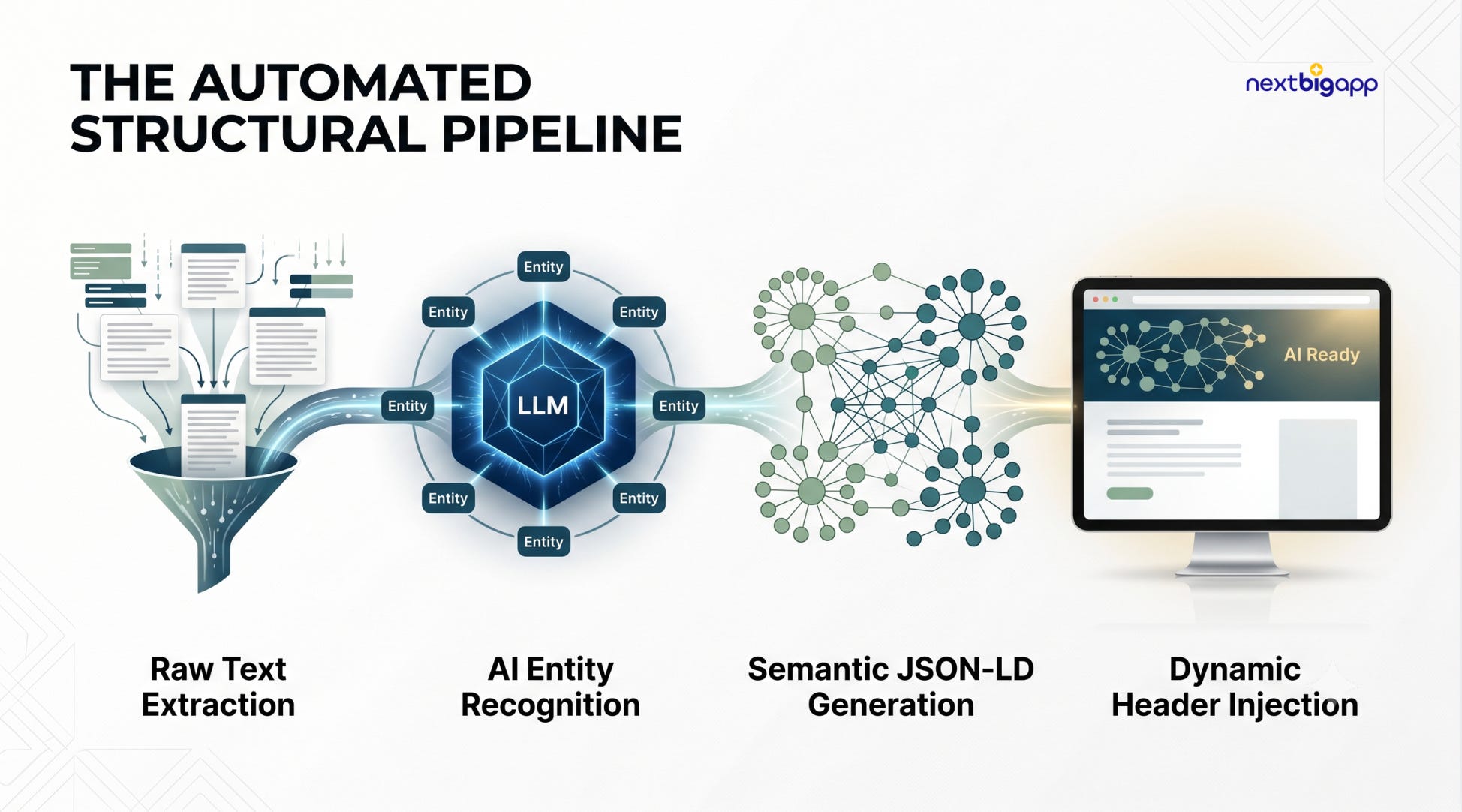
The Workflow:
Extraction: The moment a highly structured, data-rich article is published, a Python script sends the raw text to an LLM via API.
Entity Recognition: The model executes Named Entity Recognition (NER) to isolate the core concepts, internal experts, and product relationships.
Semantic Ingestion: The LLM generates a hyper-detailed, nested JSON-LD payload, mapping your internal entities directly to authoritative nodes like Wikipedia or Wikidata using
sameAstags.Dynamic Injection: The backend automatically injects this schema payload into the page header.
JSON
{
"@context": "https://schema.org",
"@type": "TechArticle",
"headline": "Overcoming the Volume Illusion",
"about": [
{
"@type": "Thing",
"name": "Knowledge Graph",
"sameAs": "https://en.wikipedia.org/wiki/Knowledge_Graph"
}
],
"mentions": [
{
"@type": "SoftwareApplication",
"name": "Neo4j",
"sameAs": "https://en.wikipedia.org/wiki/Neo4j"
}
]
}
Designing Content to Be “Chunked”
The final piece of the architectural puzzle requires an uncomfortable operational sacrifice. To be cited by an AI engine, your content must be deliberately formatted to be easily dissected and served directly on the SERP without a click.
You must trade vanity blog traffic for downstream model authority. LLMs process data in distinct vector windows (chunks). If your layout consists of dense, unstructured walls of prose, the RAG mechanism misses your core insights.
Hierarchical H-Tags: Format your H2 and H3 headers directly as explicit questions or razor-sharp, definitive statements.
TL;DR Definition Blocks: Place a highly concise, 2-to-3 sentence summary block at the absolute top of every major section. This gives the RAG loop a clean, pre-optimized text chunk to clip and cite directly inside the AI Overview.
The Strategic Realignment
The era of scaling mediocre words to capture search traffic is over.
In the age of Generative Engine Optimization, your primary metric isn’t search volume. It’s model mindshare.

Stop funding content factories that repeat what the internet already knows. Start building a hyper-structured, data-forward architecture that proves your brand is the definitive authority on the topic.
If the model doesn’t recognize your structure, the market won’t recognize your business.