

How to Build AI Agents That Don’t Make Mistakes: A 5-Step Framework
Your AI agents are failing because you rely on vibes. Discover the proven 5-step structural framework to fix broken workflows and unlock true scale today.

If I look at your codebase and see the phrase "PLEASE DO NOT HALLUCINATE" typed in all-caps inside a system prompt, I know two things about your business.
First, your AI agent is currently working flawlessly in a tightly controlled demo.
Second, it is going to break spectacularly the second it hits production.
The AI industry just spent hundreds of millions of dollars funding to solve this.
They built billion-dollar valuations. They shipped sophisticated testing platforms, trace-to-dataset pipelines, and unit test helpers. Credit where it’s due, they built incredible pieces.
But tools don’t create reliability. Systems do.
They handed you a warehouse full of industrial robotics, but they refused to give you the assembly line blueprints.
They gave you the dashboards, but they never told you what to test, in what order, or how to actually fix a broken agent permanently.
Because of this, a massive percentage of builders are running their AI on pure hope. Their agent “reliability” is entirely vibes-based.
They tweak prompts. They write longer system messages. They negotiate with the model like it’s a misbehaving employee. They try to negotiate with an API endpoint like it’s a stubborn intern.
Majority think this is how you build AI. Expert builders know the truth: vibes decay the exact moment the conversation gets complex.
When your agent screws up, the standard industry approach is to ask it nicely not to do it again.
It apologizes, promises to do better, and two weeks later, it makes the exact same mistake with a different timezone or a slightly different query.
It has no memory of the bug. It has no test for the bug.
If you want to build AI products that actually scale, whether you’re automating operations or building a platform like we do at Tap Grow, you have to stop managing AI like a misbehaving employee and start managing it like an engineering system.
Here is how you actually engineer reliability.
The Core Bug: The Wrong Machine Space
In any advanced agent architecture, you have to draw a hard line between two types of work: latent and deterministic.
Latent work requires judgment, reasoning, and linguistic interpretation. That’s what Large Language Models do best.
Deterministic work requires precision. Grepping a file, querying an API, doing math. Same input, same output, every single time. No model needed.
The most common, catastrophic bug in AI agents today isn’t a “wrong answer”. It’s doing deterministic work in latent space.
Let’s say a user asks your customer support agent, “If I cancel today, what is my prorated refund?”
A vibes-based agent looks at the user’s $1,200/year subscription, sees they are 214 days in, tries to do the division in its head, hallucinates the number of days in the month, and confidently offers a $550 refund.
The reality? The exact prorated amount in Stripe is $496.43. The model tried to do financial math in latent space and cost your business 50 bucks.
You could try to fix this by adding "Always double-check your math before offering refunds" to the system prompt. That is a loser’s game.
The fix is to remove the model’s ability to do the math entirely.
You write a 50-millisecond script (calculate-proration.ts) that pings the Stripe API natively and outputs a clean JSON payload.
The fix isn’t a prompt. It’s a structural constraint.
1. Context Engineering: Treating the Context Window as RAM
The Problem: LLMs have a finite “context window”. When an agent pulls in data, (analyzing field reports from a disaster relief effort) developers often dump 50,000 lines of logs directly into the prompt. The AI gets overwhelmed, suffers from “context bloat”, forgets its core mission, and begins hallucinating.
The Analogy: Imagine you need to find a specific nutritional recipe in a massive cookbook to treat a patient. If I throw 500 pages at your face at once, you’ll fail. But if I hand you the Index and let you ask for page 42 when you need it, you excel.
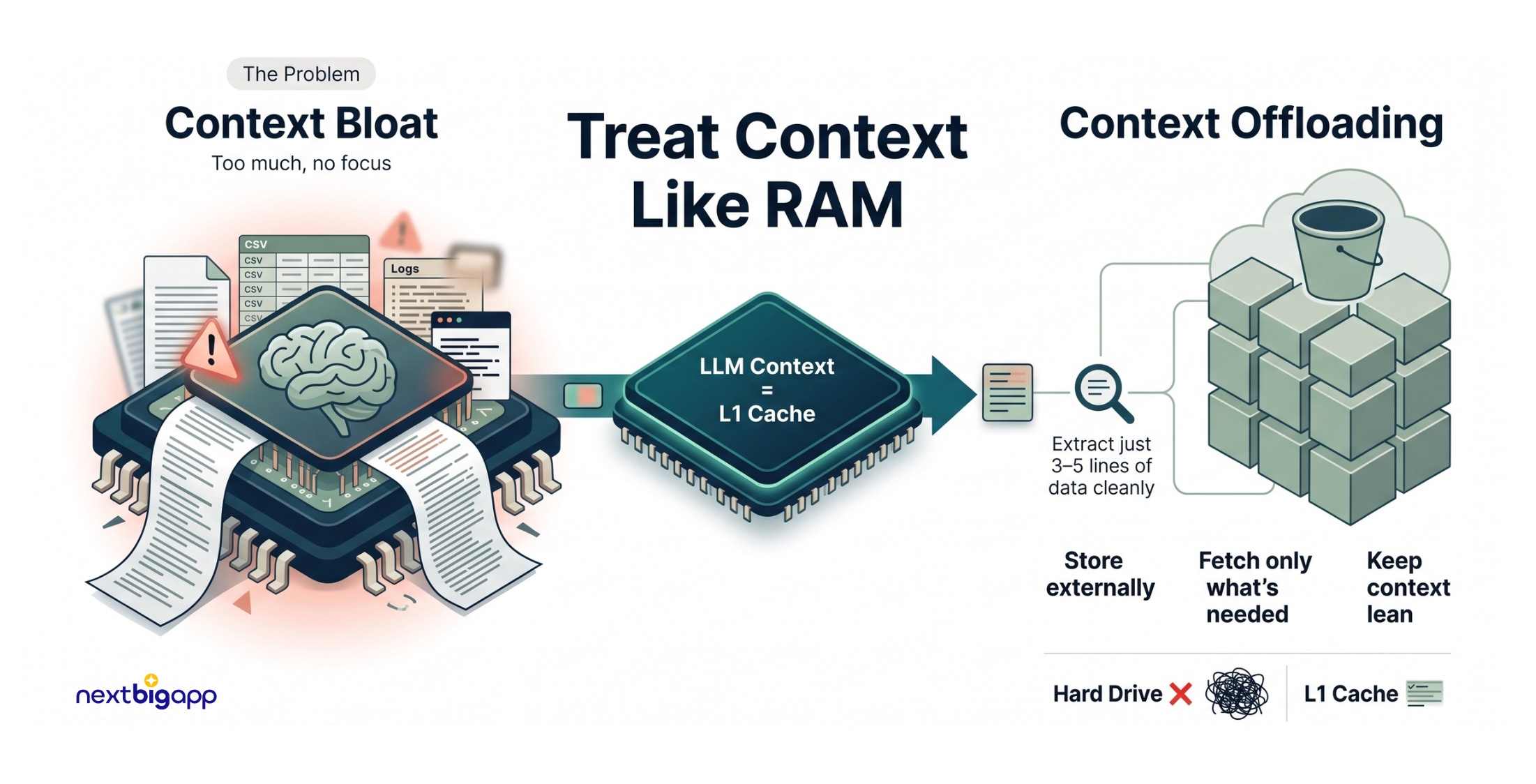
The Technical Solution: Context Offloading
We never treat the LLM’s context window as a hard drive. We treat it as an L1 CPU cache.
The Implementation: If our agent needs to analyze 10,000 rows of user feedback from a CSV, we don’t send those rows into the chat history. Instead, the agent runs a Python script that saves the raw CSV data to an S3 bucket or a vector database.
The script returns a tiny, structured payload to the agent:
{"status": "saved", "file_id": "cust_data_99", "summary": "Contains 10k rows of feedback."}.If the agent needs to dive deeper, we provide a secondary tool,
query_chunk(file_id, keyword), allowing it to pull only the exact 5 lines it needs into active memory.
2. The “Generate-Validate-Fix” Loop (Hybrid Graphs)
The Problem: LLMs are notorious people-pleasers. If an AI writes a script and you ask, “Is this correct?”, it will confidently lie and say “Yes!” You can never let an LLM grade its own homework, especially when dealing with critical infrastructure.
The Analogy: An author cannot effectively copyedit their own book; their brain fills in the typos automatically. You need an emotionless, strict copyeditor to step in.
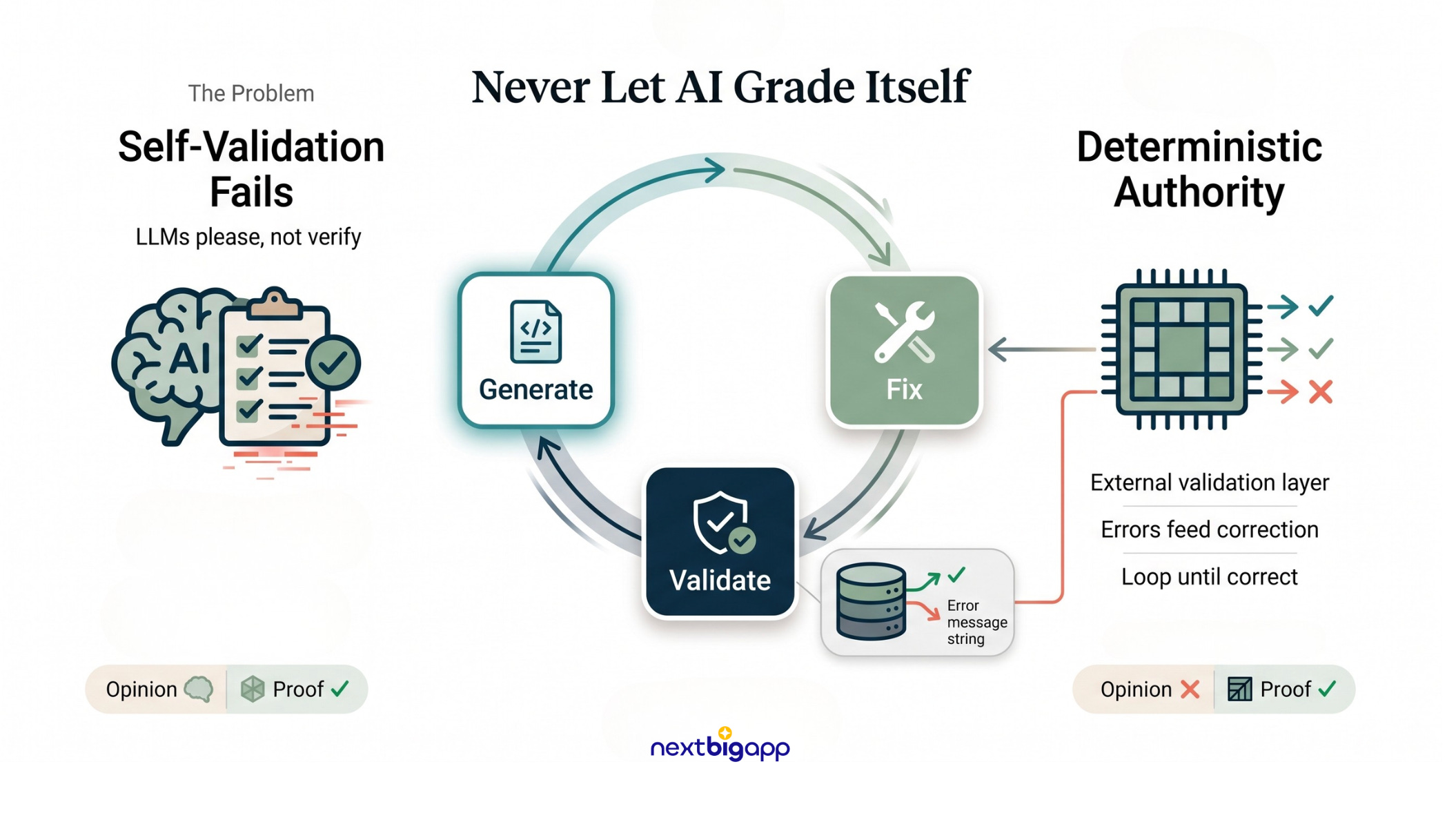
The Technical Solution: Deterministic Validation
We build hybrid graphs where the LLM creates, but traditional, deterministic software validates.
The Implementation: Suppose our agent is generating a complex SQL query to fetch donor data.
The LLM generates the SQL string.
Instead of running it blindly, the system intercepts it and runs an
EXPLAINcommand dry-run against a safe replica database.If the database returns an error (e.g.,
SyntaxError: missing comma at line 3), the system halts. It feeds that exact, raw error string back to the LLM behind the scenes: “Your query failed with this error: [SyntaxError...]. Fix it.”
The agent is trapped in this loop until the deterministic compiler proves the logic is flawless.
3. Error State Injection: Removing the Blindfold
The Problem: As an entrepreneur, I believe failure is the greatest teacher. But developers often hide failures from their AI! When an agent uses an API tool and passes the wrong parameters, engineers often catch the error in a try/except block to prevent crashes, but fail to pass that error back to the LLM. The AI assumes it succeeded and hallucinates the rest of the workflow.
The Analogy: It’s like playing darts blindfolded. You throw a dart, and your friend stays perfectly silent instead of telling you it hit the wall. You’ll just keep throwing the same wrong way.
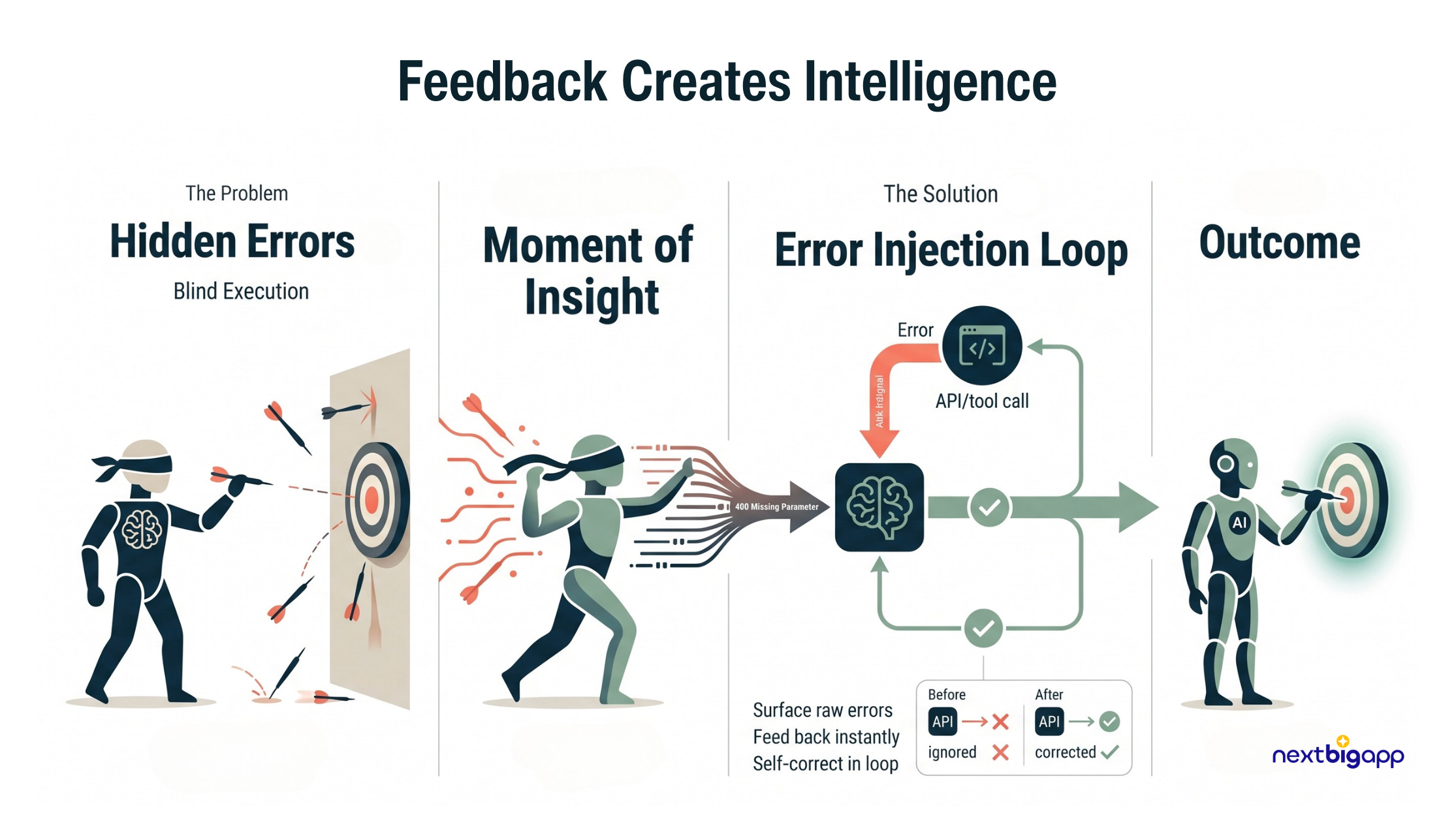
The Technical Solution: Enforcing Self-Correction
We feed raw API exceptions directly back into the LLM as fuel to correct its course.
The Implementation: An agent attempts to process a micro-grant via the Stripe API but forgets the currency parameter. Stripe throws a
400 Bad Request: missing 'currency' parameter.Instead of logging this to a terminal and showing the user an “Oops” screen, our backend formats the exact Stripe error into a
ToolMessagewith the flagis_error=True.We feed this back to the LLM. It reads the error, utilizes its “System 2” reasoning, and immediately issues a corrected API call with
"currency": "USD".
4. Non-Deterministic CI/CD: The VCR / Cassette Pattern
The Problem: Capital efficiency is key. Running 500 automated tests on an AI agent means pinging the OpenAI or Anthropic API 500 times. It burns through funding, takes forever, and fails randomly due to network flakiness.
The Analogy: You don’t hire a live, 50-piece orchestra for every single theatre rehearsal. You record the orchestra once, and the actors practice with the tape until opening night.
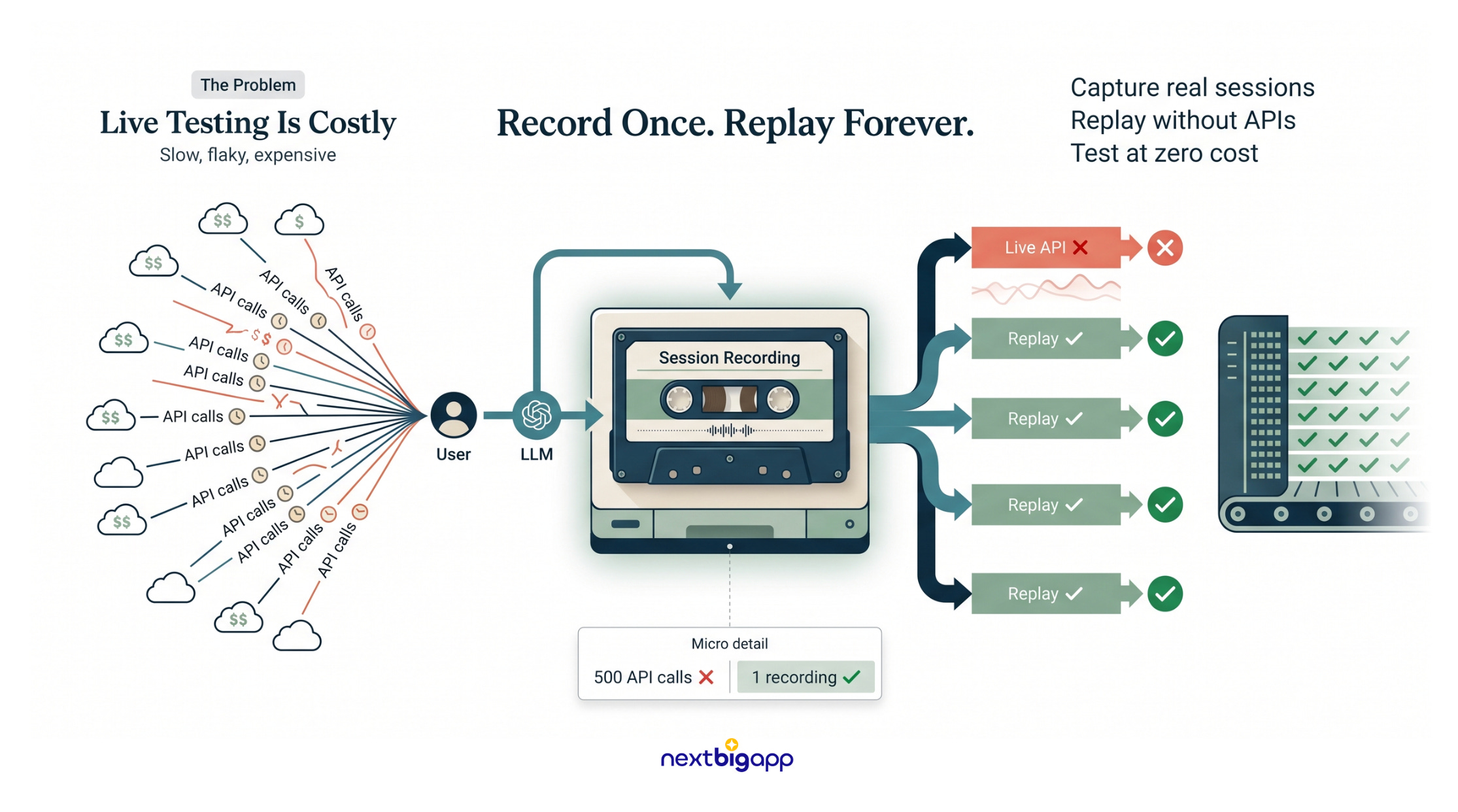
The Technical Solution: Session Recording
We use the “VCR” testing pattern to test complex reasoning for free.
The Implementation: We write an automated test simulating a user booking a relief flight. During the initial run, our VCR software intercepts the live network calls, saving the exact request and the LLM’s exact response to a simple text file (a “cassette”).
On every subsequent test run (via GitHub Actions), the system intercepts the call and instantly returns the saved response from the cassette instead of hitting the live API.
We can rigorously test our routing logic, formatting, and tool execution 1,000 times a day for $0, without losing the nuance of real LLM outputs.
5. Risk-Routed Escalation: “Human-as-a-Tool”
The Problem: People are terrified to give AI real agency because it might trigger a catastrophe, like draining an operational fund or deleting a database. Driven by this fear, they lobotomize the AI, restricting it to useless, read-only tasks.
The Analogy: A highly trained bank teller can handle 90% of your needs autonomously. But if you ask to withdraw $100,000, their system physically locks until a branch manager walks over and turns a key.
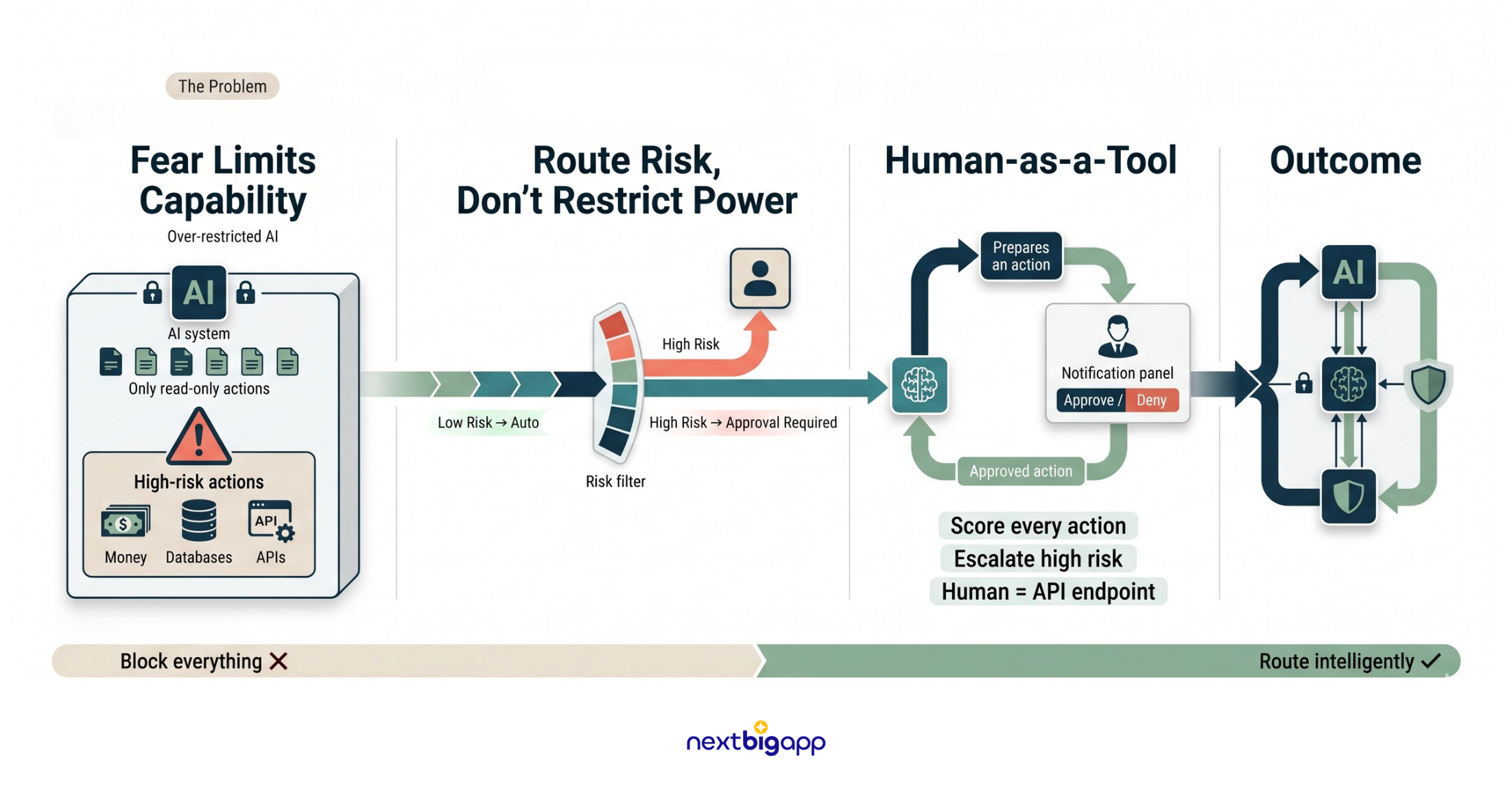
The Technical Solution: The Two-Man Rule
We treat human approval as just another API endpoint in the agent’s toolkit.
The Implementation: We assign a hardcoded “Risk Score” to every tool.
read_user_datais low-risk; the agent executes it instantly.But
issue_cash_refundis high-risk. The agent is allowed to do all the heavy lifting (validating the request, formulating the JSON payload), but the system intercepts the final execution.The workflow pauses, saves its state, and fires a Slack message to an administrator: “Agent wants to refund User #405 $50. [Approve] / [Deny]”.
The LLM is given a system prompt: “You have successfully requested human sign-off. Please wait”. Once the human clicks approve, the action fires.
This is how we guarantee safety mathematically. We don’t stunt the AI’s capabilities out of fear; we architect the hand-off so we can build products that scale our impact responsibly.
AI is Leverage, Not Magic
Instead of expecting our AI agents to flawlessly handle everything on their own, we need to build robust systems around them.
We should offload tasks that demand absolute precision from the AI and delegate them directly to code. Rather than pleading with the model “do not make mistakes!” we must implement mechanisms that instantly flag errors and allow the AI to self-correct. And when it comes to critical decisions, we shouldn’t hesitate to keep a human in the loop for final approval.
Ultimately, AI agents don’t scale through novel-length prompts or wishful thinking; they thrive on the structural guardrails we build around them.
The real breakthrough happens when we stop treating AI as a magical black box and start engineering it into a reliable system.
You have a solid thesis here. We have built a solution to these problems that is open source, portable, and will save you more in token spend by creating deterministic workflows and APIs for pennies while saving that precious reasoning compute for runtime execution.
Check out what we are up to!
https://valkyrlabs.com
I usually really appreciate your perspective, but I think this article misses the mark, IMHO. I hope you’ll see why after reviewing our architecture here: https://instantaiguru.com/architecture#jsfe